Power of Robots.txt and Meta Robots Tags for Effective Indexation and Crawl Management
The robots.txt file and the <meta name="robots"> tag play crucial roles in controlling how search engines interact with and index the content on a website. These elements are important for SEO (Search Engine Optimization) as they help webmasters communicate with search engines about which parts of their site should be crawled and indexed.
Robots.txt File:
- Crawling Directives:
- The
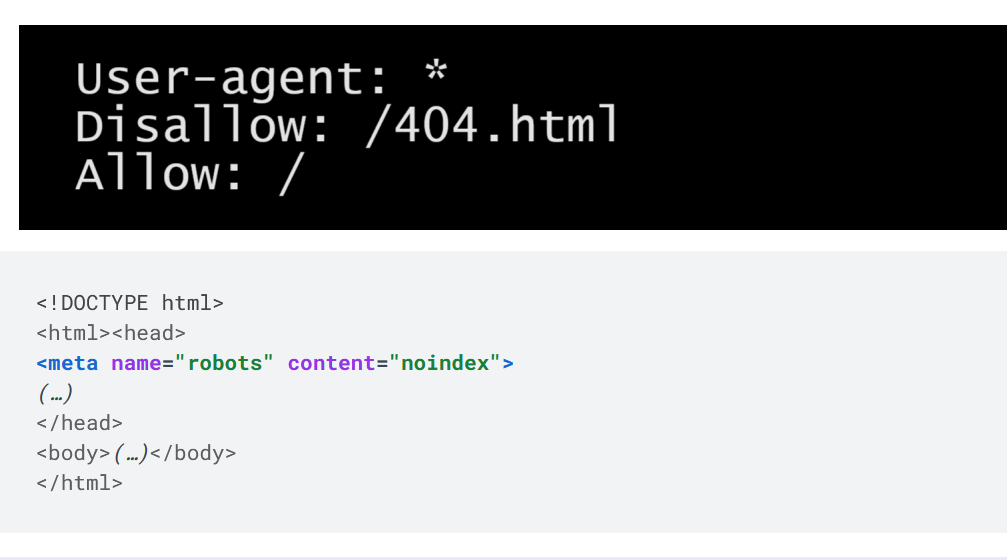
robots.txtfile is a text file placed at the root of a website that provides instructions to web crawlers about which pages or sections should not be crawled or indexed. - It contains directives like “User-agent” (specifying the search engine bots) and “Disallow” (specifying the URLs or directories that should not be crawled).
- The
- Crawl Budget Management:
- By using the
robots.txtfile, webmasters can manage the crawl budget efficiently. The crawl budget refers to the amount of time and resources a search engine allocates to crawling a specific site.
- By using the
- Preventing Indexation:
- Sections of a site that are sensitive, duplicate, or not meant for public view can be disallowed in the
robots.txtfile to prevent them from being indexed by search engines.
- Sections of a site that are sensitive, duplicate, or not meant for public view can be disallowed in the
Meta Robots Tag:
- Noindex and Nofollow:
- The
<meta name="robots">tag is placed within the HTML<head>section of a specific webpage and can be used to provide page-level instructions. - The “noindex” directive instructs search engines not to index a particular page, keeping it out of search engine results.
- The “nofollow” directive tells search engines not to follow the links on that page, preventing link equity from being passed to the linked pages.
- The
- Index and Follow:
- Conversely, if you want search engines to index a page and follow its links, you can use the “index” and “follow” directives in the
<meta name="robots">tag.
- Conversely, if you want search engines to index a page and follow its links, you can use the “index” and “follow” directives in the

Even if you don’t have an SEO strategy, your agency will evaluate your website from an SEO perspective.
Impact on SEO:
PSA: I was hired as SEO expert witness on a case where a small local biz hired an agency to revamp their site and do SEO.
— Chris Silver Smith (@si1very) January 18, 2024
The agency left "discourage search engines from indexing this site" enabled in WordPress when they launched.🤦♂️
Almost 2 yrs impacted before owner realized! pic.twitter.com/LhuvdqO3VS
- Control over Indexation:
- Proper use of the
robots.txtfile and the<meta name="robots">tag allows webmasters to have control over what content is indexed by search engines, helping to present the most relevant and valuable information to users.
- Proper use of the
- Preventing Duplicate Content Issues:
- These directives help in preventing duplicate content issues by excluding certain pages from being indexed, ensuring that search engines focus on the preferred version of content.
- Crawl Efficiency:
- Efficient use of these directives can improve crawl efficiency by directing search engine bots to focus on the most important and relevant parts of the website.
In summary, both the robots.txt file and the <meta name="robots"> tag are important tools in SEO for controlling how search engines access and index website content. They allow webmasters to guide search engine bots, manage crawl budgets, and ensure that the most valuable content is presented to users in search engine results.